|
|
DancingBox: A Lightweight MoCap System for Character Animation from Physical Proxies
Haocheng Yuan,
Adrien Bousseau,
Hao Pan,
Lei Zhong,
Changjian Li
CHI 2026
Honorable Mention Award
|

|
MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
Zhe Li,
Yisheng He,
Lei Zhong,
…, and others,
Weihao Yuan
Arxiv 2024
|
|
|
Sketch2Anim: Towards Transferring Sketch Storyboards into 3D Animation
Lei Zhong,
Chuan Guo,
Yiming Xie,
Jiawei Wang,
Changjian Li
ACM Transactions on Graphics (Proc. SIGGRAPH 2025)
Selected by SIGGRAPH as a technical paper highlight in the official press releases
|
|
|
Seeking Physics in Diffusion Noise
Chujun Tang,
Lei Zhong,
Fangqiang Ding
ArXiv 2026
|
|
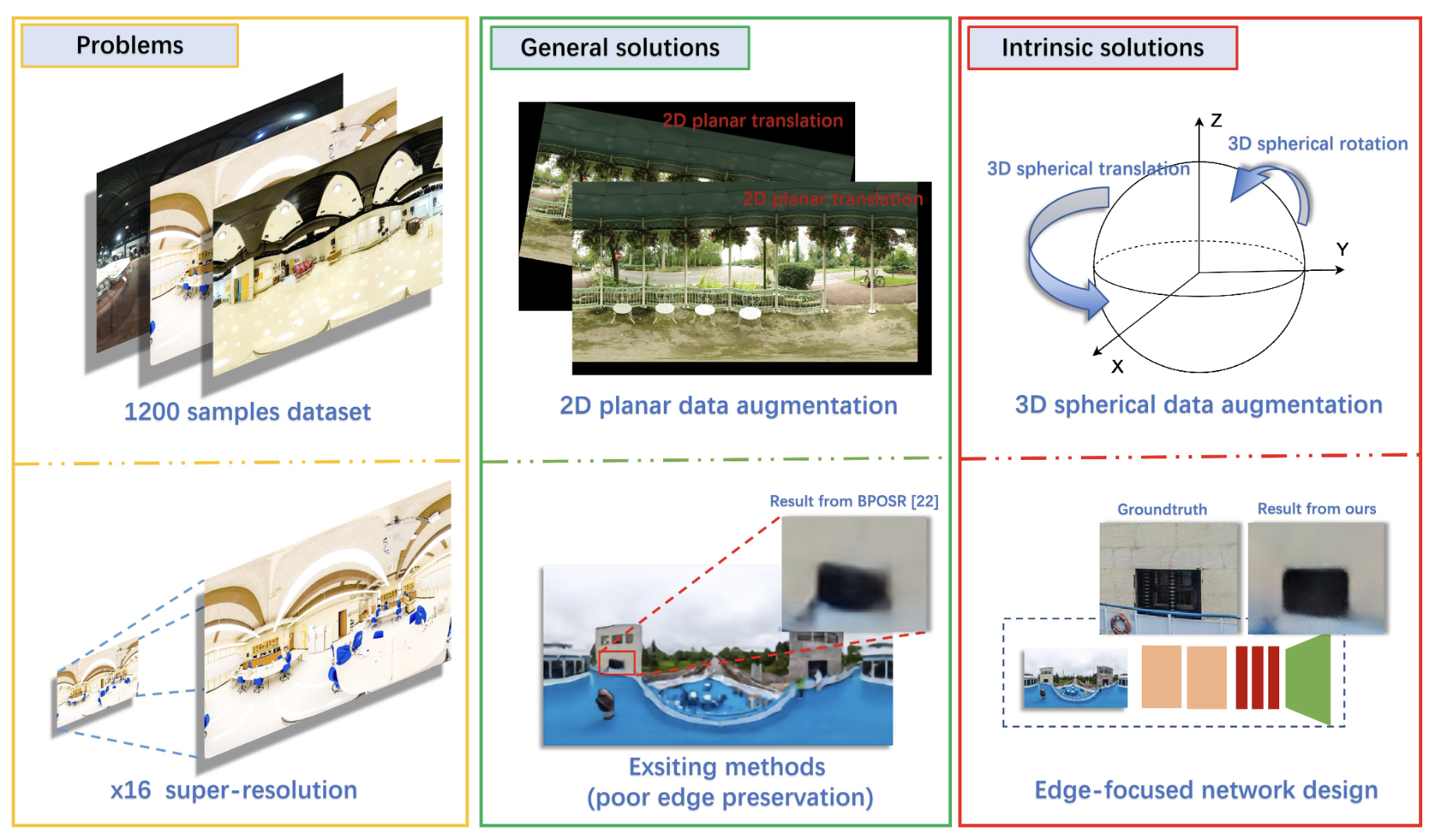
Edge-Focused Super-Resolution for Omnidirectional Images with Spherical Geometric Augmentation
Shaolin Wang,
Yuying Li,
Lei Zhong,
Shigang Li,
Jianfeng Li
CVPR 2026
|
|
|
PoseTraj: Pose-Aware Trajectory Control in Video Diffusion
Longbin Ji,
Lei Zhong,
Wei Pengfei,
Changjian Li
CVPR 2025
|
|
|
SMooDi: Stylized Motion Diffusion Model
Lei Zhong,
Yiming Xie,
Varun Jampani,
Deqing Sun,
Huaizu Jiang
ECCV 2024
|
|
|
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Yiming Xie,
Varun Jampani,
Lei Zhong,
Deqing Sun,
Huaizu Jiang
ICLR 2024
|

|
Aesthetic-guided Outward Image Cropping
Lei Zhong,
Feng-Heng Li,
Hao-Zhi Huang,
Yong Zhang,
Shao-Ping Lu,
Jue Wang
ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2021)
|

|
A Graph-Structured Representation with BRNN for Static-based Facial Expression Recognition
Lei Zhong,
Changmin Bai,
Jianfeng Li,
Tong Chen,
Shigang Li,
Yiguang Liu
FG 2019
|